“No data, no delivery”
A problem common to many CEP operators is operating with insufficient or even blank parcel data. Unfortunately, in focusing on the delivery aspect of their operations, CEP operators can sometimes overlook the importance of resolving the issue of getting the data into the system and the consequences can be costly.
Insufficient data on parcels occurs where readable barcodes do not contain the data needed to process the parcels properly. So while operators can read destinations on the labels and move the parcels out of their systems and on the right track, information about the senders, receivers and whether the parcel is express or economy gets lost. So while CEP operators think they’re taking appropriate action in quickly processing the parcel by its address only, in fact they can often deny themselves valuable revenue. It is both expensive to the operator if it processes an economy freight parcel as an express parcel and an express parcel as economy.
What’s more, the items “disappear” in the system, seeming to not move from their original place of hand-in, arriving at next stop terminals as unexpected “ghost items”. This is problematic for sending and receiving customers who are tracking and tracing items. It also creates problems for couriers who, with sufficient data, cannot plan their parts in the parcel flows.
Finally, items with insufficient data soon become very costly for sorting facilities. If these items make up just 5-10 percent of parcel flows, the hubs begin to lose money in terms of time, space and human resources needed to resolve the issue. To make matters worse, hubs cannot settle accounts when their handling processes have not been recorded. They find themselves in the situation of providing services for free, impacting on future viability.
In contrast, there are large distribution centres that may refuse to process parcels that have blank or insufficient data.
Check out: The parcel distributor’s guide to e-commerce logistics.
Through data enrichment practices and the use of video coding system (VCS) and optical character recognition (OCR) technologies, however, hubs are able to work around this problem. For example, oftentimes the parcel text will be sufficient for an operator to know where the parcel is next headed. The operator can send the parcel on its way and while it is en route, enrich the data by finding details such as a precise address.
Applying these technologies means that by the time the parcel arrives at the next terminal stop, the incomplete data will be resolved. The important point here is hubs should try to solve these data issues when they first appear and avoid pushing the problems further down the line.
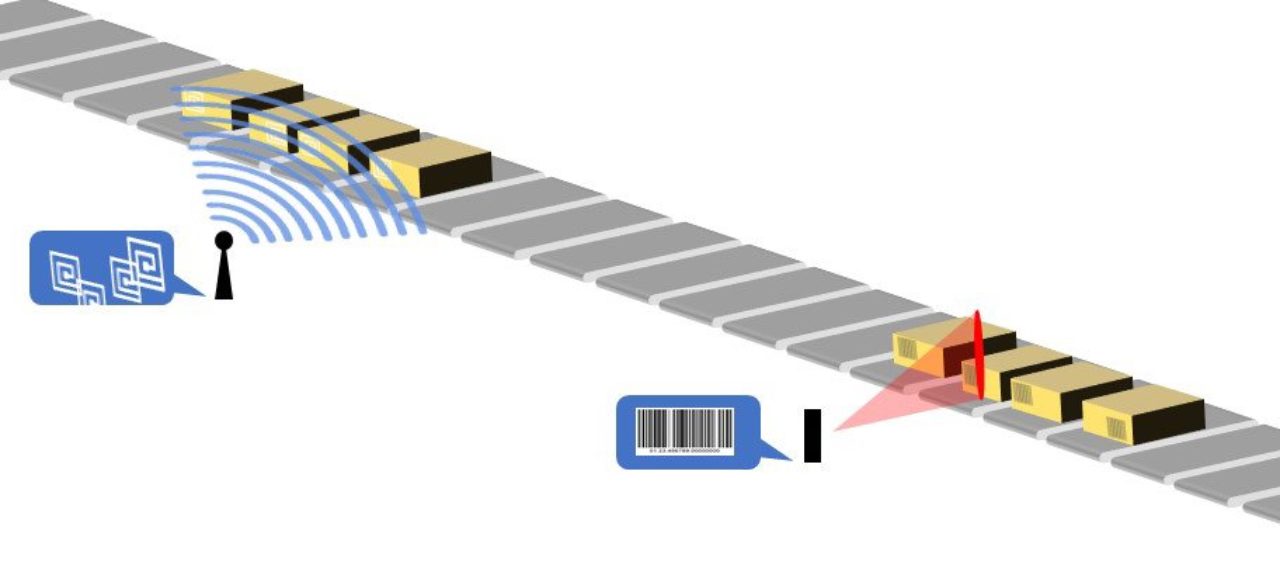
RFID – or not?
RFID chips (radio frequency identification) are passive chips which share their data with a reader only when activated by radio waves. Making a contactless payment with your credit card at the supermarket is an example of RFID technology.
In parcel processing, RFID technology involves placing small electronic chips into parcels which can send messages through radio signals to an operator. RFID chips would then include all the same data as a barcode, just with a higher read rate. As such, RFID technology might seem like a good option for sortation and tracking, however, it’s actually better suited for other purposes at distribution centres.
RFID technology has evolved considerably since it was introduced to the industry some 15 years ago. From a parcel tracking perspective, the problem is simply that the technology is not specific. In fact, radio frequency is so scattered that a scanner cannot determine the position of an RFID tag – only its area. This means that if a hub is sorting numerous parcels in an automated flow, a bunch of signals from all the parcels will be sent to the scanner, making it impossible to know the exact position of an individual parcel.