„Keine Daten, keine Zustellung“
Ein Problem, das viele KEP-Dienste gemeinsam haben, ist das Arbeiten mit unzureichenden oder sogar leeren Paketdaten. Leider können KEP-Dienste bei der Fokussierung auf den Zustellaspekt ihrer Abläufe manchmal die Bedeutung der Lösung des Problems, die Daten in das System zu bekommen, übersehen, und die Folgen können kostspielig sein.
Unzureichende Daten auf Paketen treten dort auf, wo lesbare Barcodes nicht die Daten enthalten, die benötigt werden, um die Pakete ordnungsgemäß zu bearbeiten. Während die Betreiber also die Ziele auf den Etiketten lesen und die Pakete aus ihren Systemen und auf den richtigen Weg bringen können, gehen Informationen über die Absender, Empfänger und darüber, ob das Paket Express oder Economy ist, verloren. Während KEP-Dienste also denken, dass sie angemessene Maßnahmen ergreifen, indem sie das Paket schnell nur nach seiner Adresse bearbeiten, können sie sich in der Tat oft wertvolle Einnahmen verweigern. Es ist sowohl teuer für den Betreiber, wenn er ein Economy-Frachtpaket als Expresspaket und ein Expresspaket als Economy bearbeitet.
Darüber hinaus „verschwinden“ die Artikel im System und scheinen sich nicht von ihrem ursprünglichen Ort der Übergabe zu bewegen, sondern kommen als unerwartete „Geisterartikel“ an den nächsten Terminalstationen an. Dies ist problematisch für sendende und empfangende Kunden, die Artikel verfolgen und zurückverfolgen. Es schafft auch Probleme für Kuriere, die mit ausreichenden Daten ihre Teile in den Paketflüssen nicht planen können.
Schließlich werden Artikel mit unzureichenden Daten bald sehr kostspielig für Sortieranlagen. Wenn diese Artikel nur 5-10 Prozent der Paketflüsse ausmachen, beginnen die Hubs Geld in Bezug auf Zeit, Platz und Personalressourcen zu verlieren, die zur Lösung des Problems benötigt werden. Erschwerend kommt hinzu, dass Hubs keine Konten begleichen können, wenn ihre Bearbeitungsprozesse nicht aufgezeichnet wurden. Sie befinden sich in der Situation, Dienstleistungen kostenlos zu erbringen, was sich auf die zukünftige Rentabilität auswirkt.
Im Gegensatz dazu gibt es große Verteilzentren, die sich weigern können, Pakete zu bearbeiten, die leere oder unzureichende Daten haben.
Schauen Sie sich an: Der Leitfaden des Paketverteilers zur E-Commerce-Logistik.
Durch Datenanreicherungspraktiken und den Einsatz von Videocodierungssystemen (VCS) und OCR-Technologien (Optical Character Recognition) können Hubs dieses Problem jedoch umgehen. Oftmals reicht beispielsweise der Pakettext aus, damit ein Betreiber weiß, wohin das Paket als nächstes geht. Der Betreiber kann das Paket auf den Weg schicken und während es unterwegs ist, die Daten anreichern, indem er Details wie eine genaue Adresse findet.
Die Anwendung dieser Technologien bedeutet, dass bis zum Eintreffen des Pakets an der nächsten Terminalstation die unvollständigen Daten behoben sind. Der wichtige Punkt hier ist, dass Hubs versuchen sollten, diese Datenprobleme zu lösen, wenn sie zum ersten Mal auftreten, und vermeiden sollten, die Probleme weiter nach unten zu schieben.
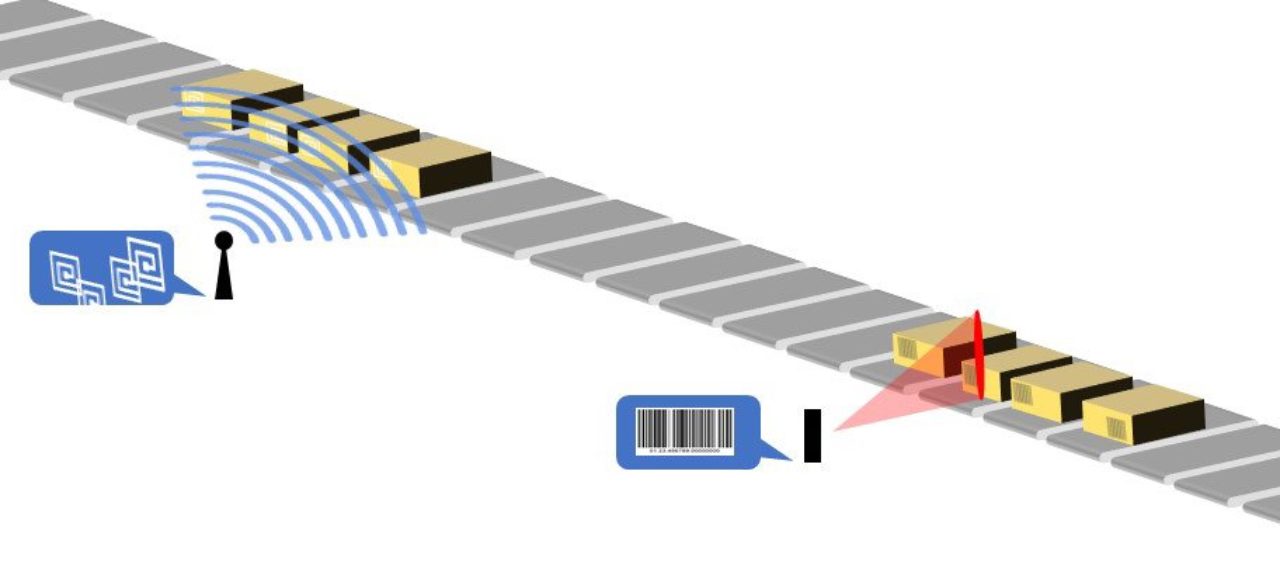
RFID – oder nicht?
RFID-Chips (Radio Frequency Identification) sind passive Chips, die ihre Daten nur dann mit einem Lesegerät teilen, wenn sie durch Funkwellen aktiviert werden. Eine kontaktlose Zahlung mit Ihrer Kreditkarte im Supermarkt ist ein Beispiel für RFID-Technologie.
Bei der Paketbearbeitung beinhaltet die RFID-Technologie das Platzieren kleiner elektronischer Chips in Pakete, die Nachrichten über Funksignale an einen Betreiber senden können. RFID-Chips würden dann alle gleichen Daten wie ein Barcode enthalten, nur mit einer höheren Leseraten. Daher mag die RFID-Technologie wie eine gute Option für die Sortierung und Verfolgung erscheinen, aber sie ist eigentlich besser für andere Zwecke in Verteilzentren geeignet.
Die RFID-Technologie hat sich seit ihrer Einführung in der Branche vor etwa 15 Jahren erheblich weiterentwickelt. Aus Sicht der Paketverfolgung ist das Problem einfach, dass die Technologie nicht spezifisch ist. Tatsächlich ist die Funkfrequenz so verstreut, dass ein Scanner die Position eines RFID-Tags nicht bestimmen kann – nur seinen Bereich. Dies bedeutet, dass, wenn ein Hub zahlreiche Pakete in einem automatisierten Fluss sortiert, ein Bündel von Signalen von allen Paketen an den Scanner gesendet wird, was es unmöglich macht, die genaue Position eines einzelnen Pakets zu kennen.