« Pas de données, pas de livraison »
Un problème courant pour de nombreux opérateurs CEP est de fonctionner avec des données de colis insuffisantes, voire vierges. Malheureusement, en se concentrant sur l’aspect de la livraison de leurs opérations, les opérateurs CEP peuvent parfois négliger l’importance de résoudre le problème de l’introduction des données dans le système et les conséquences peuvent être coûteuses.
Des données insuffisantes sur les colis se produisent lorsque les codes-barres lisibles ne contiennent pas les données nécessaires pour traiter correctement les colis. Ainsi, alors que les opérateurs peuvent lire les destinations sur les étiquettes et sortir les colis de leurs systèmes et sur la bonne voie, les informations sur les expéditeurs, les destinataires et si le colis est express ou économique sont perdues. Ainsi, alors que les opérateurs CEP pensent prendre les mesures appropriées en traitant rapidement le colis par son adresse uniquement, en fait, ils peuvent souvent se priver de revenus précieux. Il est coûteux pour l’opérateur de traiter un colis de fret économique comme un colis express et un colis express comme économique.
De plus, les articles « disparaissent » dans le système, semblant ne pas bouger de leur lieu de dépôt d’origine, arrivant aux terminaux d’arrêt suivants en tant qu’« articles fantômes » inattendus. Ceci est problématique pour les clients expéditeurs et destinataires qui suivent les articles. Cela crée également des problèmes pour les coursiers qui, avec des données suffisantes, ne peuvent pas planifier leurs pièces dans les flux de colis.
Enfin, les articles avec des données insuffisantes deviennent rapidement très coûteux pour les installations de tri. Si ces articles représentent seulement 5 à 10 % des flux de colis, les hubs commencent à perdre de l’argent en termes de temps, d’espace et de ressources humaines nécessaires pour résoudre le problème. Pour aggraver les choses, les hubs ne peuvent pas régler les comptes lorsque leurs processus de manutention n’ont pas été enregistrés. Ils se retrouvent dans la situation de fournir des services gratuitement, ce qui a un impact sur la viabilité future.
En revanche, il existe de grands centres de distribution qui peuvent refuser de traiter les colis qui ont des données vierges ou insuffisantes.
Consultez : Le guide du distributeur de colis pour la logistique du commerce électronique.
Grâce aux pratiques d’enrichissement des données et à l’utilisation de systèmes de codage vidéo (VCS) et de technologies de reconnaissance optique de caractères (OCR), les hubs sont toutefois en mesure de contourner ce problème. Par exemple, souvent, le texte du colis sera suffisant pour qu’un opérateur sache où le colis est ensuite dirigé. L’opérateur peut envoyer le colis sur son chemin et, pendant qu’il est en route, enrichir les données en trouvant des détails tels qu’une adresse précise.
L’application de ces technologies signifie qu’au moment où le colis arrive au prochain arrêt du terminal, les données incomplètes seront résolues. Le point important ici est que les hubs devraient essayer de résoudre ces problèmes de données lorsqu’ils apparaissent pour la première fois et éviter de repousser les problèmes plus loin.
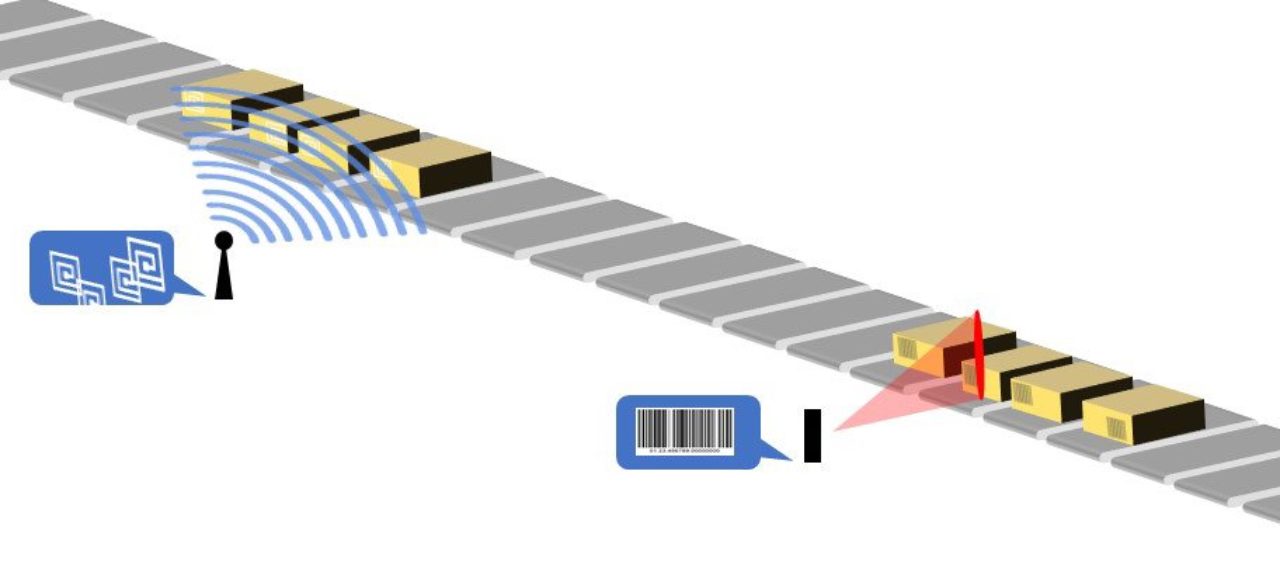
RFID – ou pas ?
Les puces RFID (identification par radiofréquence) sont des puces passives qui partagent leurs données avec un lecteur uniquement lorsqu’elles sont activées par des ondes radio. Effectuer un paiement sans contact avec votre carte de crédit au supermarché est un exemple de technologie RFID.
Dans le traitement des colis, la technologie RFID implique de placer de petites puces électroniques dans les colis qui peuvent envoyer des messages via des signaux radio à un opérateur. Les puces RFID incluraient alors toutes les mêmes données qu’un code-barres, juste avec un taux de lecture plus élevé. En tant que telle, la technologie RFID peut sembler être une bonne option pour le tri et le suivi, cependant, elle est en fait mieux adaptée à d’autres fins dans les centres de distribution.
La technologie RFID a considérablement évolué depuis son introduction dans l’industrie il y a environ 15 ans. Du point de vue du suivi des colis, le problème est simplement que la technologie n’est pas spécifique. En fait, la radiofréquence est tellement dispersée qu’un scanner ne peut pas déterminer la position d’une étiquette RFID – seulement sa zone. Cela signifie que si un hub trie de nombreux colis dans un flux automatisé, un tas de signaux de tous les colis seront envoyés au scanner, ce qui rendra impossible de connaître la position exacte d’un colis individuel.