“Sin datos, no hay entrega”
Un problema común a muchos operadores de CEP es operar con datos de paquetes insuficientes o incluso en blanco. Desafortunadamente, al centrarse en el aspecto de la entrega de sus operaciones, los operadores de CEP a veces pueden pasar por alto la importancia de resolver el problema de ingresar los datos en el sistema y las consecuencias pueden ser costosas.
Los datos insuficientes en los paquetes se producen cuando los códigos de barras legibles no contienen los datos necesarios para procesar los paquetes correctamente. Por lo tanto, si bien los operadores pueden leer los destinos en las etiquetas y sacar los paquetes de sus sistemas y en la dirección correcta, la información sobre los remitentes, los receptores y si el paquete es urgente o económico se pierde. Por lo tanto, si bien los operadores de CEP piensan que están tomando las medidas adecuadas para procesar rápidamente el paquete solo por su dirección, de hecho, a menudo pueden negarse ingresos valiosos. Es costoso para el operador si procesa un paquete de carga económica como un paquete urgente y un paquete urgente como económico.
Además, los artículos “desaparecen” en el sistema, aparentemente no se mueven de su lugar original de entrega, llegando a las terminales de la siguiente parada como “artículos fantasma” inesperados. Esto es problemático para los clientes que envían y reciben artículos de seguimiento. También crea problemas para los mensajeros que, con datos suficientes, no pueden planificar sus piezas en los flujos de paquetes.
Finalmente, los artículos con datos insuficientes pronto se vuelven muy costosos para las instalaciones de clasificación. Si estos artículos representan solo el 5-10 por ciento de los flujos de paquetes, los centros comienzan a perder dinero en términos de tiempo, espacio y recursos humanos necesarios para resolver el problema. Para empeorar las cosas, los centros no pueden liquidar cuentas cuando no se han registrado sus procesos de manipulación. Se encuentran en la situación de proporcionar servicios de forma gratuita, lo que afecta la viabilidad futura.
Por el contrario, existen grandes centros de distribución que pueden negarse a procesar paquetes que tienen datos en blanco o insuficientes.
Consulte: La guía del distribuidor de paquetes para la logística de comercio electrónico.
Sin embargo, a través de prácticas de enriquecimiento de datos y el uso de sistemas de codificación de vídeo (VCS) y tecnologías de reconocimiento óptico de caracteres (OCR), los centros pueden solucionar este problema. Por ejemplo, a menudo el texto del paquete será suficiente para que un operador sepa a dónde se dirige el paquete a continuación. El operador puede enviar el paquete en su camino y, mientras está en ruta, enriquecer los datos buscando detalles como una dirección precisa.
La aplicación de estas tecnologías significa que para cuando el paquete llegue a la siguiente parada de la terminal, los datos incompletos se resolverán. El punto importante aquí es que los centros deben tratar de resolver estos problemas de datos cuando aparecen por primera vez y evitar empujar los problemas más abajo en la línea.
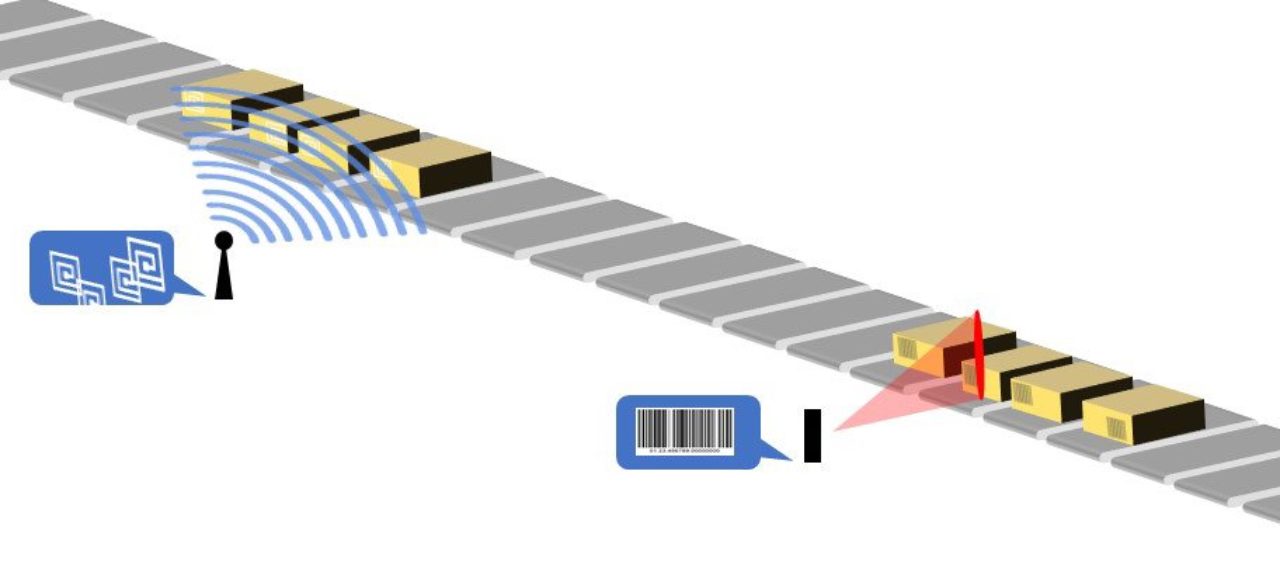
RFID – ¿o no?
Los chips RFID (identificación por radiofrecuencia) son chips pasivos que comparten sus datos con un lector solo cuando se activan por ondas de radio. Realizar un pago sin contacto con su tarjeta de crédito en el supermercado es un ejemplo de tecnología RFID.
En el procesamiento de paquetes, la tecnología RFID implica colocar pequeños chips electrónicos en los paquetes que pueden enviar mensajes a través de señales de radio a un operador. Los chips RFID incluirían entonces los mismos datos que un código de barras, solo que con una tasa de lectura más alta. Como tal, la tecnología RFID puede parecer una buena opción para la clasificación y el seguimiento, sin embargo, en realidad es más adecuada para otros fines en los centros de distribución.
La tecnología RFID ha evolucionado considerablemente desde que se introdujo en la industria hace unos 15 años. Desde una perspectiva de seguimiento de paquetes, el problema es simplemente que la tecnología no es específica. De hecho, la radiofrecuencia está tan dispersa que un escáner no puede determinar la posición de una etiqueta RFID, solo su área. Esto significa que si un centro está clasificando numerosos paquetes en un flujo automatizado, un montón de señales de todos los paquetes se enviarán al escáner, lo que hace imposible conocer la posición exacta de un paquete individual.